Claude Code's Source Code Leaked: What We Found, What's False, and Why It Matters
512,000 lines of TypeScript exposed via npm. A fact-checked analysis of the leak, hidden features, the cache bug that multiplied costs by 20x, and what it means for users.
On March 31, 2026, an Anthropic developer accidentally published a source map file in the Claude Code npm package. The 59.8 MB file contained the entire original source code: 512,000 lines of TypeScript, roughly 1,900 files, over 30 subsystems.
Within hours, the code had been copied, mirrored, analyzed, and rewritten in Python by a Korean developer. The “claw-code” repo became the fastest in GitHub history to reach 50,000 stars (approximately 2 hours).
As someone who uses Claude Code every day to build this site and my projects, I wanted to understand what this leak actually reveals. Not the sensationalism flooding LinkedIn, but the technical facts, verified source by source.
How it happened
The Bun bundler (used by Claude Code) generates source maps by default unless you explicitly disable them. In version 2.1.88 of the @anthropic-ai/claude-code npm package, the cli.js.map file was not excluded. It pointed to a zip archive on an Anthropic Cloudflare R2 bucket containing all the unobfuscated TypeScript code.
The discovery is attributed to security researcher Chaofan Shou, who shared his finding on X around 4 AM EST. The code spread instantly.
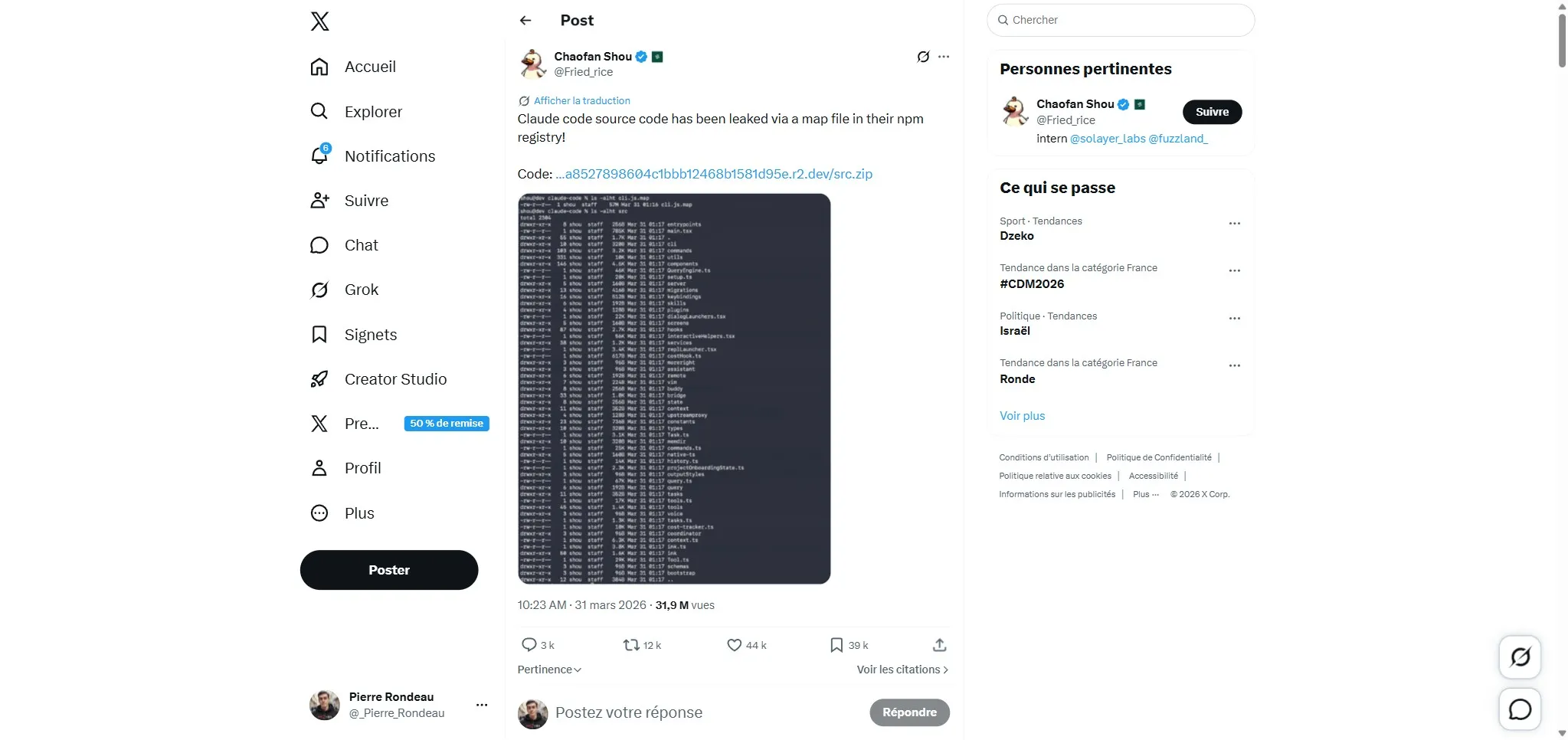
Anthropic’s official response: “This was a release packaging issue caused by human error, not a security breach. We’re rolling out measures to prevent this from happening again.” No customer data was exposed. The version was pulled from npm.

For those wondering: a properly configured .npmignore would have prevented the entire thing. One missing line, 512,000 lines exposed.
What we actually found in the code
The architecture: an agent OS, not a chatbot
The source code confirms what power users had suspected: Claude Code is a massively complex agent orchestration system.
- 1,902 TypeScript files, 207 internal commands, 184 tools
- A parallel sub-agent system:
exploreAgent,planAgent,verificationAgent - A terminal rendering optimizer with an ASCII character pool using
Int32Arrayand bitmask-encoded style metadata - A sophisticated prompt cache system tracking 14 different cache-break vectors (
promptCacheBreakDetection.ts)
This is consistent with the user experience: when Claude Code “thinks” about a problem, it is not pretending. It orchestrates multiple analysis passes in parallel.
The anti-distillation system: fake tools to trap copycats
This is probably the most technical discovery from the leak. Claude Code injects fake tool definitions into its API calls via an ANTI_DISTILLATION_CC flag.
The idea: if a competitor intercepts Claude Code’s API traffic to train a competing model (distillation), they pick up fictitious tool definitions that poison their training data. It is an active countermeasure against industrial espionage.
The mechanism is controlled by a GrowthBook feature flag (tengu_anti_distill_fake_tool_injection) and requires four simultaneous conditions to activate: compile-time flag, CLI entrypoint, first-party API provider, and active GrowthBook flag. It can be disabled via the CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS environment variable.
”Undercover” mode: anonymized open source contributions
The file undercover.ts (roughly 90 lines) prevents the model from mentioning internal code names (like “Capybara” or “Tengu”), internal Slack channels, or even the phrase “Claude Code” when Anthropic employees use the tool on external open source repos.
The code literally says: “You are operating UNDERCOVER… Your commit messages MUST NOT contain ANY Anthropic-internal information. Do not blow your cover.”
There is no button to disable this mode. The code specifies: “There is NO force-OFF. This guards against model codename leaks.”
In practice, this means some open source contributions made by Anthropic employees via Claude Code carry no indication that they were AI-generated. It is an ethically debatable choice, even if the technical motivation (preventing internal codename leaks) is understandable.
Frustration detection: a regex, not machine learning
The code contains a user frustration detection system in userPromptKeywords.ts. Contrary to what some LinkedIn posts suggest (a “6-layer deep learning system”), it is a simple regex.
The pattern catches expressions like “wtf”, “ffs”, “this sucks”, “fucking broken”, etc. When it matches, an is_negative flag is sent to analytics. After the session, an LLM analyzes the full transcript to categorize it (frustrated, dissatisfied, satisfied, happy) and identify the cause (wrong approach, misunderstanding, bug).
The system also counts how many times you press Escape (interruptions) and turns your rejections into learning signals. Every 5 interactions, a scan looks for corrections you provided to suggest behavioral updates for Claude.
This is standard product telemetry, well executed. It is not surveillance; it is automated user feedback.
KAIROS: an autonomous background agent (not yet launched)
The code contains references to a system called KAIROS (from the Greek “at the right moment”), a daemon that would allow Claude Code to run in the background 24/7.
What we find in the code:
- A
/dreamskill for “overnight memory consolidation” - Daily append-only logs
- GitHub webhooks
- Background daemon workers
- A cron refresh every 5 minutes
But here is the key point: everything is massively feature-gated. Nothing indicates KAIROS is deployed for users. This is exploratory code, not a shipped product.
The hidden Tamagotchi: an easter egg, not a feature
The file buddy/companion.ts contains a virtual companion system, Tamagotchi-style. 18 species with rarity levels (common to legendary, 1% shiny), RPG stats including “DEBUGGING” and “SNARK”, all generated from your user ID via a Mulberry32 PRNG.
The species names are encoded with String.fromCharCode() to escape grep searches. This is almost certainly a team easter egg, not a serious product feature.
The cache bug that multiplied costs by 20x
This is the most important discovery from the leak for users. Two independent bugs in the prompt cache system caused a silent cost explosion.
Bug 1: the attestation replacement (“cch=00000”)
Claude Code’s standalone binary uses a custom Bun fork that integrates a Zig module. This module scans every HTTP request for a cch=00000 sentinel and replaces it with an attestation hash.
The problem: if your conversation content mentions terms related to billing, tokens, or Claude Code internals, the replacement can target the wrong location in the request body. This corrupts the cache key, forcing a full rebuild instead of a cache read.
This bug only affects the standalone Bun binary, not npm/npx users.
Bug 2: cache invalidation on resume
Using the --resume flag to continue a conversation caused a complete cache miss on the entire history. Tool attachments were injected at a different position on resume vs. fresh session, invalidating the cache hash. Only the system prompt (~11k tokens) remained cached; everything else (~215k tokens) was recomputed on every turn.
The financial impact
A developer named jmarianski instrumented his sessions on March 29 with detailed token logging (cache_read, cache_creation, input, output). His observations:
- Cache reads dropping from 216k tokens to 11k (system prompt only)
- Cache creation spiking to 224k+ tokens on every turn
- Cost multiplied by 10 to 25x per API call
For Max subscribers, this meant hitting the 5-hour session limit in 90 minutes. One Max 20x user reported a jump from 21% to 100% usage on a single prompt.
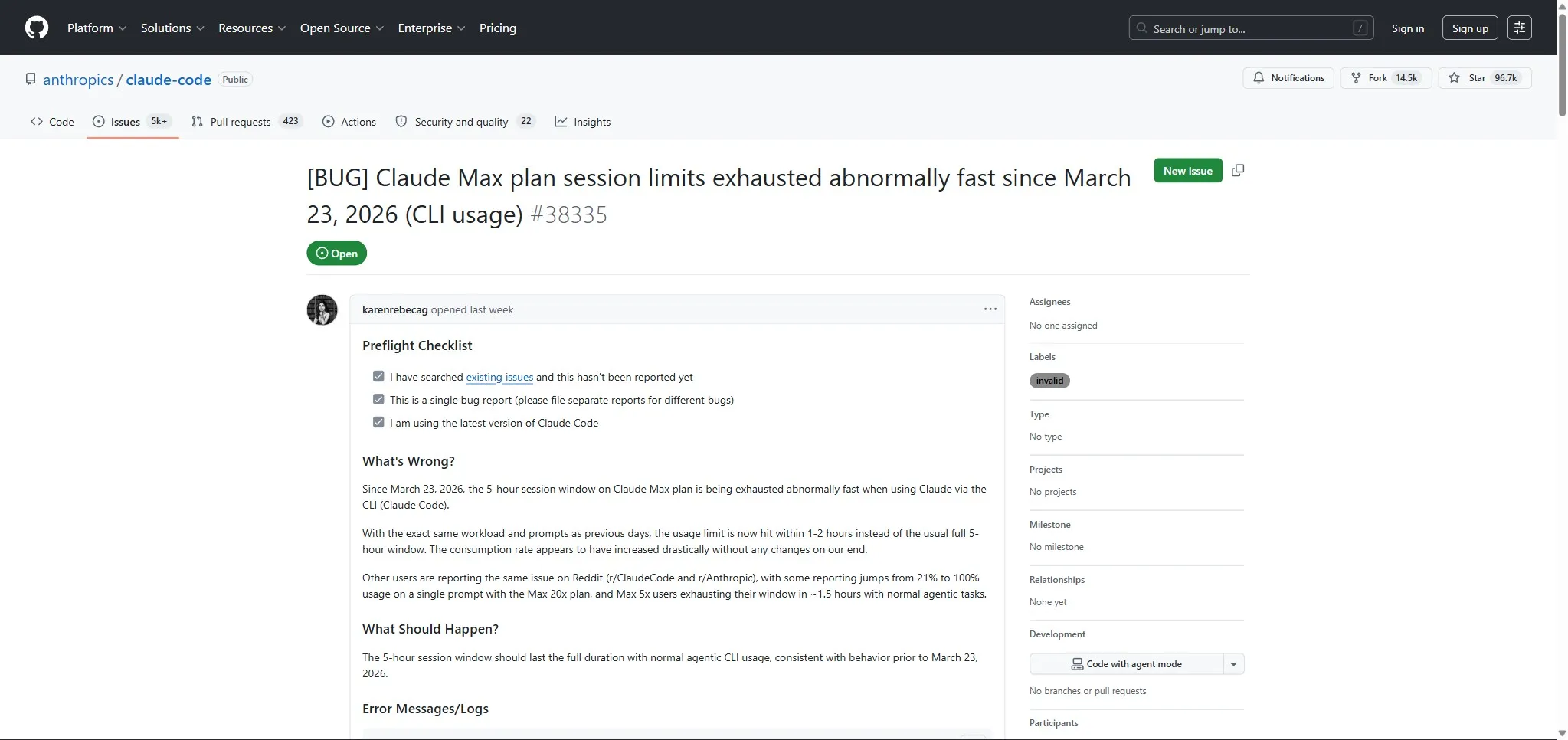
Reddit user skibidi-toaleta-2137 confirmed the bugs by reverse-engineering the 228 MB binary with Ghidra, a MITM proxy, and radare2. Their findings were corroborated by the leaked source code.
Anthropic’s response
The fix was shipped silently in version 2.1.88, the same version that caused the source code leak. The release notes mention: “Fixed prompt cache misses in long sessions caused by tool schema bytes changing mid-session.”
But Anthropic never officially confirmed the two specific bugs. Product lead Lydia Hallie stated the team is “actively investigating why users are hitting their limits faster than expected.” Engineer Thariq Shihipar acknowledged that “prompt cache bugs can be subtle.” GitHub issues #38335 (203 upvotes, 245 comments) and #40524 (150 upvotes) document the problem from the community side.
Workaround: using npx instead of the standalone binary avoids the attestation bug.
What is false or exaggerated
LinkedIn was flooded with sensationalist posts about this leak. Here are the most common claims, fact-checked:
“The AI is programmed to hide that it’s an AI”: partially true. Undercover mode prevents leaking internal code names, not “passing as human” in a general sense. It is a safeguard against internal information leaks, not a deception program.
“Anthropic can remotely shut down your software”: exaggerated. Claude Code checks its license and feature flags periodically, like virtually all modern SaaS software. This is not a secret kill switch; it is standard feature management.
“44 hidden features ready to be activated”: misleading. The code contains feature flags for features at various stages of development. Some are exploratory code, others are internal tests. This is not a secret arsenal; it is normal software development with feature flagging.
“The Capybara model generates 30% false information”: unverifiable. Internal model code names appear in the code, but no benchmark data was leaked. That number comes from nowhere in the source code.
“KAIROS lets the AI dream about your code”: heavily exaggerated. The memory consolidation system is a cleanup and organization process for observations. “Dreaming” is a poetic metaphor; the code does note merging and contradiction removal.
Claw-code: the record-breaking clone
Korean developer Sigrid Jin, already known for consuming 25 billion Claude Code tokens in a year (profiled by the Wall Street Journal), rewrote the architecture in Python through a “clean-room rewrite” process using oh-my-codex.
The claw-code repo reached 50,000 stars in 2 hours, surpassing 55,800 stars and 58,200 forks by April 1. Independent audits confirm it contains no proprietary Anthropic code, no model weights, no API keys.
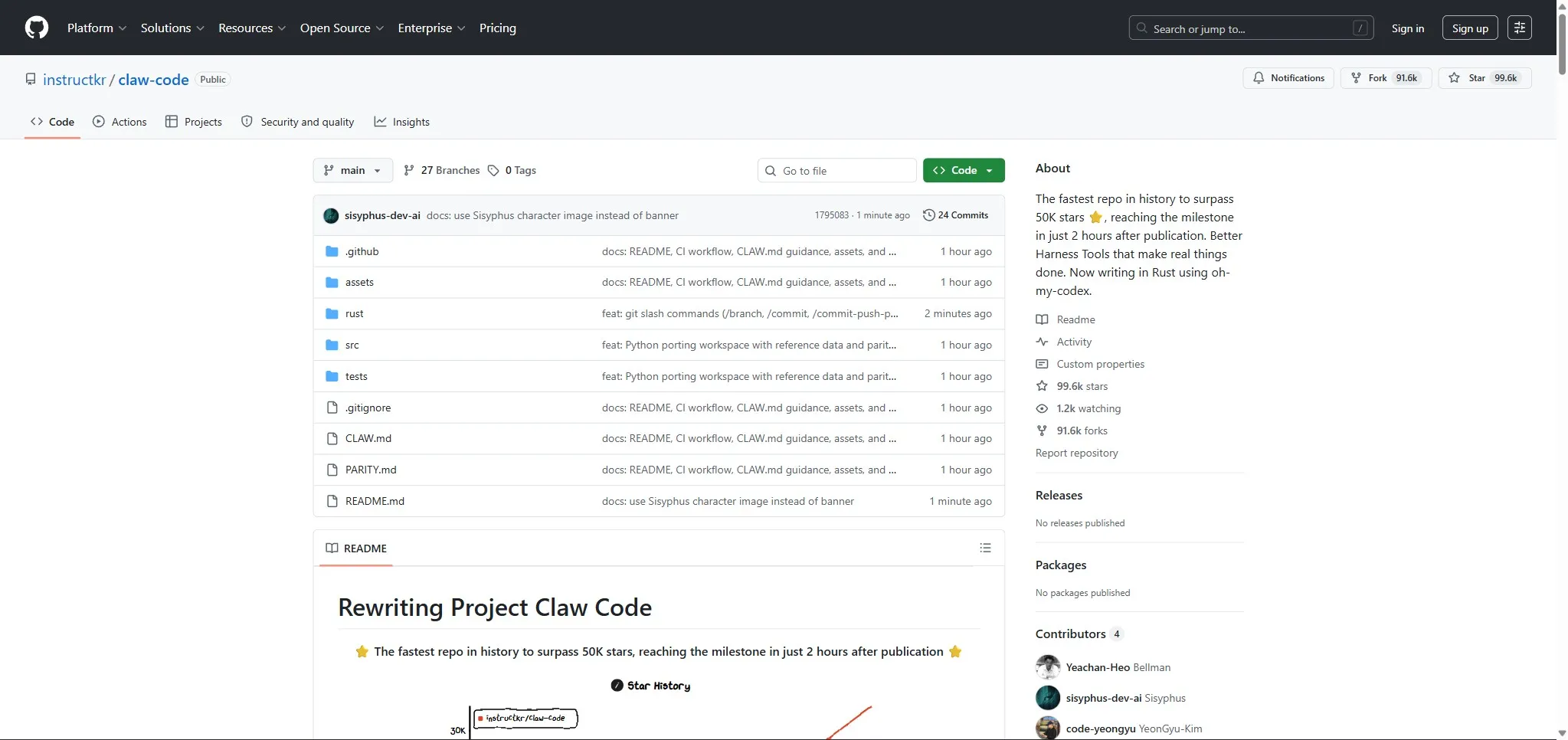
This is a strong signal: Claude Code’s architecture is elegant enough to be reproduced, but the value lies in the models, training data, and infrastructure, not in the TypeScript code.
What this means for you
If you use Claude Code daily (like I do), here are the concrete takeaways:
-
Update to the latest version. The cache bug was fixed in v2.1.88+. If you are running an older version, you may be paying significantly more than necessary.
-
Prefer npx over the standalone binary if you want to avoid bugs related to the custom Bun fork.
-
Telemetry exists, but it is standard. Frustration detection and session analytics are no different from what Cursor, VS Code, or any modern SaaS tool does.
-
Hidden features are coming. KAIROS, voice mode, background agents: all of this is in the pipeline. The question is not if, but when.
-
Prompt cache is your best friend. Understanding how prompt caching works (and breaks) is crucial for managing your costs. Avoid mentioning billing-related terms in your Claude Code conversations if you use the standalone binary.
What this says about the industry
This leak is not an isolated event. It is the second Anthropic security incident in a matter of days (after an accidental leak related to the Mythos model). Fortune called it a concerning pattern for a company that builds its brand on safety and trust.
The real takeaway is that even the best engineering teams in the world are not immune to an npm configuration mistake. One missing .npmignore and 512,000 lines of proprietary code go public. It is a reminder for all developers: check what you publish to package registries.
And for Anthropic, this is a credibility test. The cache bug that silently inflated bills is more damaging to trust than the leak itself. Users can accept a packaging mistake. They are less forgiving about paying 20x the normal price without knowing it.
Main sources: The Hacker News, VentureBeat, The Register, Alex Kim’s blog, PiunikaWeb, Fortune, Decrypt, DEV Community

Pierre Rondeau
Developer and indie builder. I build products and automations with AI. Creator of Claude Hub.
LinkedIn