Le code source de Claude Code a fuité : ce qu'on y a trouvé, ce qui est faux, et pourquoi ça compte
512 000 lignes de TypeScript exposées via npm. Analyse fact-checkée du leak, des features cachées, du bug de cache qui multipliait les coûts par 20, et de ce que ça change pour les utilisateurs.
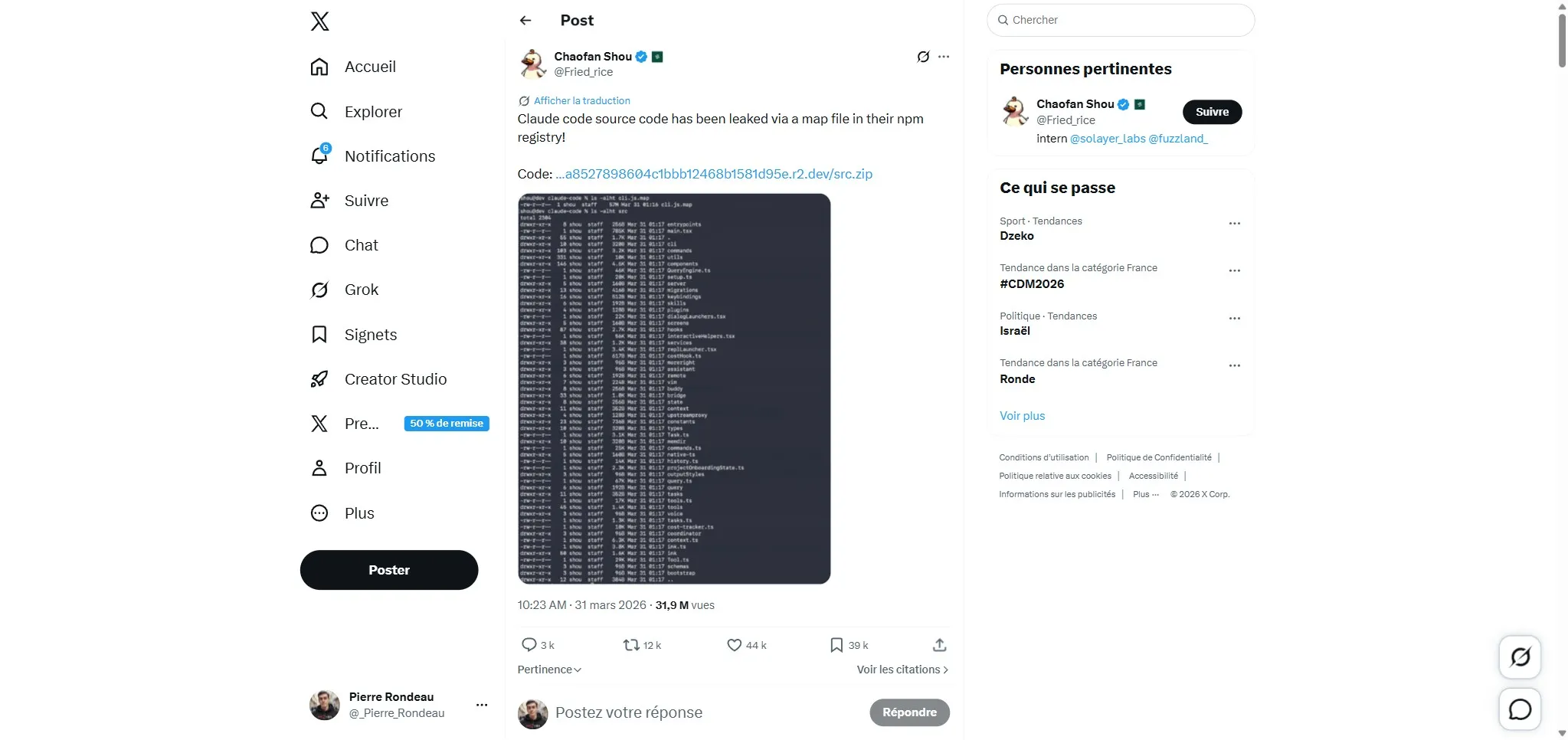
Le 31 mars 2026, un développeur d’Anthropic a publié par erreur un fichier source map dans le package npm de Claude Code. Ce fichier de 59,8 Mo contenait l’intégralité du code source original : 512 000 lignes de TypeScript, environ 1 900 fichiers, plus de 30 sous-systèmes.
En quelques heures, le code était copié, mirroré, analysé, et réécrit en Python par un développeur coréen. Le repo “claw-code” est devenu le plus rapide de l’histoire de GitHub à atteindre 50 000 étoiles (environ 2 heures).
Comme j’utilise Claude Code tous les jours pour construire ce site et mes projets, j’ai voulu comprendre ce que ce leak révèle vraiment. Pas le sensationnalisme qu’on lit partout sur LinkedIn, mais les faits techniques, vérifiés source par source.
Comment c’est arrivé
Le bundler Bun (utilisé par Claude Code) génère des source maps par défaut. Sauf si tu les désactives explicitement. Dans la version 2.1.88 du package npm @anthropic-ai/claude-code, le fichier cli.js.map n’a pas été exclu. Il pointait vers une archive zip sur un bucket Cloudflare R2 d’Anthropic, contenant tout le code TypeScript non obfusqué.
La découverte est attribuée au chercheur en sécurité Chaofan Shou, qui a partagé sa trouvaille sur X vers 4h du matin (heure EST). Le code s’est propagé instantanément.
La réponse officielle d’Anthropic : “This was a release packaging issue caused by human error, not a security breach. We’re rolling out measures to prevent this from happening again.” Aucune donnée client n’a été exposée. La version a été retirée de npm.

Pour ceux qui se posent la question : un .npmignore correctement configuré aurait suffi à empêcher tout ça. Une ligne manquante, 512 000 lignes exposées.
Ce qu’on a vraiment trouvé dans le code
L’architecture : un OS pour agents, pas un chatbot
Le code source confirme ce que les utilisateurs avancés soupçonnaient : Claude Code est un système d’orchestration d’agents massivement complexe.
- 1 902 fichiers TypeScript, 207 commandes internes, 184 outils
- Un système de sous-agents parallèles :
exploreAgent,planAgent,verificationAgent - Un optimiseur de rendu terminal avec un pool de caractères ASCII en
Int32Arrayet des métadonnées de style encodées en bitmask - Un système de cache de prompts sophistiqué qui traque 14 vecteurs de cache-break différents (
promptCacheBreakDetection.ts)
C’est cohérent avec l’expérience utilisateur : quand Claude Code “réfléchit” à un problème, il ne fait pas semblant. Il orchestre plusieurs passes d’analyse en parallèle.
Le système anti-distillation : des faux outils pour piéger les copieurs
C’est probablement la découverte la plus technique du leak. Claude Code injecte de faux outils (tool definitions) dans ses appels API via un flag ANTI_DISTILLATION_CC.
Le principe : si un concurrent intercepte le trafic API de Claude Code pour entraîner un modèle concurrent (distillation), il récupère des définitions d’outils fictives qui empoisonnent ses données d’entraînement. C’est une contre-mesure active contre l’espionnage industriel.
Le mécanisme est contrôlé par un feature flag GrowthBook (tengu_anti_distill_fake_tool_injection) et nécessite quatre conditions simultanées pour s’activer : flag compile-time, entrypoint CLI, fournisseur API first-party, et flag GrowthBook actif. Il peut être désactivé via la variable d’environnement CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS.
Le mode “Undercover” : des contributions open source anonymisées
Le fichier undercover.ts (environ 90 lignes) empêche le modèle de mentionner des noms de code internes (comme “Capybara” ou “Tengu”), des channels Slack internes, ou même la phrase “Claude Code” quand des employés d’Anthropic utilisent l’outil sur des repos open source externes.
Le code dit littéralement : “You are operating UNDERCOVER… Your commit messages MUST NOT contain ANY Anthropic-internal information. Do not blow your cover.”
Il n’y a pas de bouton pour désactiver ce mode. Le code précise : “There is NO force-OFF. This guards against model codename leaks.”
Concrètement, ça veut dire que certaines contributions open source faites par des employés Anthropic via Claude Code ne portent aucune indication qu’elles ont été générées par IA. C’est un choix éthique discutable, même si la motivation technique (ne pas leaker de noms de code internes) est compréhensible.
La détection de frustration : un regex, pas du machine learning
Le code contient un système de détection de frustration utilisateur dans userPromptKeywords.ts. Contrairement à ce que certains posts LinkedIn suggèrent (un “système à 6 couches de deep learning”), c’est un simple regex.
Le pattern détecte des expressions comme “wtf”, “ffs”, “this sucks”, “fucking broken”, etc. Quand il matche, un flag is_negative est envoyé dans les analytics. Après la session, un LLM analyse la transcription complète pour la catégoriser (frustrated, dissatisfied, satisfied, happy) et identifier la cause (mauvaise approche, malentendu, bug).
Le système compte aussi le nombre de fois où tu appuies sur Escape (interruptions) et transforme tes rejections en signaux d’apprentissage. Toutes les 5 interactions, un scan cherche les corrections que tu as données pour proposer des mises à jour du comportement de Claude.
C’est de la télémétrie produit classique, bien exécutée. Ce n’est pas de la surveillance ; c’est du feedback utilisateur automatisé.
KAIROS : un agent autonome en arrière-plan (pas encore lancé)
Le code contient des références à un système nommé KAIROS (du grec “au bon moment”), un daemon qui permettrait à Claude Code de tourner en arrière-plan 24h/24.
Ce qu’on trouve dans le code :
- Un skill
/dreampour la “consolidation nocturne de mémoire” - Des logs quotidiens en append-only
- Des webhooks GitHub
- Des workers daemon en arrière-plan
- Un cron de rafraîchissement toutes les 5 minutes
Mais attention : tout est massivement feature-gated. Rien n’indique que KAIROS soit déployé pour les utilisateurs. C’est du code exploratoire, pas un produit lancé.
Le Tamagotchi caché : un easter egg, pas une feature
Le fichier buddy/companion.ts contient un système de compagnon virtuel type Tamagotchi. 18 espèces avec des niveaux de rareté (common à legendary, 1% shiny), des stats RPG incluant “DEBUGGING” et “SNARK”, le tout généré depuis ton identifiant utilisateur via un PRNG Mulberry32.
Les noms des espèces sont encodés avec String.fromCharCode() pour échapper aux recherches grep. C’est très probablement un easter egg d’équipe, pas une feature produit sérieuse.
Le bug de cache qui multipliait les coûts par 20
C’est la découverte la plus importante du leak pour les utilisateurs. Deux bugs indépendants dans le système de cache de prompts causaient une explosion silencieuse des coûts.
Bug 1 : le remplacement d’attestation (“cch=00000”)
Le binaire standalone de Claude Code utilise un fork custom de Bun qui intègre un module Zig. Ce module scanne chaque requête HTTP pour trouver un sentinel cch=00000 et le remplace par un hash d’attestation.
Le problème : si le contenu de ta conversation mentionne des termes liés à la facturation, aux tokens, ou aux internals de Claude Code, le remplacement peut cibler le mauvais endroit dans le corps de la requête. Ça corrompt la clé de cache, forçant un rebuild complet au lieu d’un cache read.
Ce bug n’affecte que le binaire Bun standalone, pas les utilisateurs npm/npx.
Bug 2 : l’invalidation du cache sur resume
Utiliser le flag --resume pour reprendre une conversation causait un cache miss complet sur tout l’historique. Les attachements d’outils étaient injectés à une position différente sur resume vs. session fraîche, invalidant le hash du cache. Seul le system prompt (~11k tokens) restait caché ; tout le reste (~215k tokens) était recalculé à chaque tour.
L’impact financier
Un développeur nommé jmarianski a instrumenté ses sessions le 29 mars avec un logging détaillé des tokens (cache_read, cache_creation, input, output). Ses observations :
- Cache reads qui chutent de 216k tokens à 11k (system prompt seul)
- Cache creation qui explose à 224k+ tokens à chaque tour
- Coût multiplié par 10 à 25x par appel API
Pour les abonnés Max, ça signifiait atteindre la limite de session de 5 heures en 90 minutes. Un utilisateur Max 20x a rapporté un saut de 21% à 100% d’utilisation sur un seul prompt.
Le Reddit user skibidi-toaleta-2137 a confirmé les bugs en rétro-ingéniérant le binaire de 228 Mo avec Ghidra, un proxy MITM et radare2. Ses découvertes ont été corroborées par le code source leaké.
La réponse d’Anthropic
Le fix a été livré silencieusement dans la version 2.1.88, la même version qui a causé le leak du code source. Les notes de version mentionnent : “Fixed prompt cache misses in long sessions caused by tool schema bytes changing mid-session.”
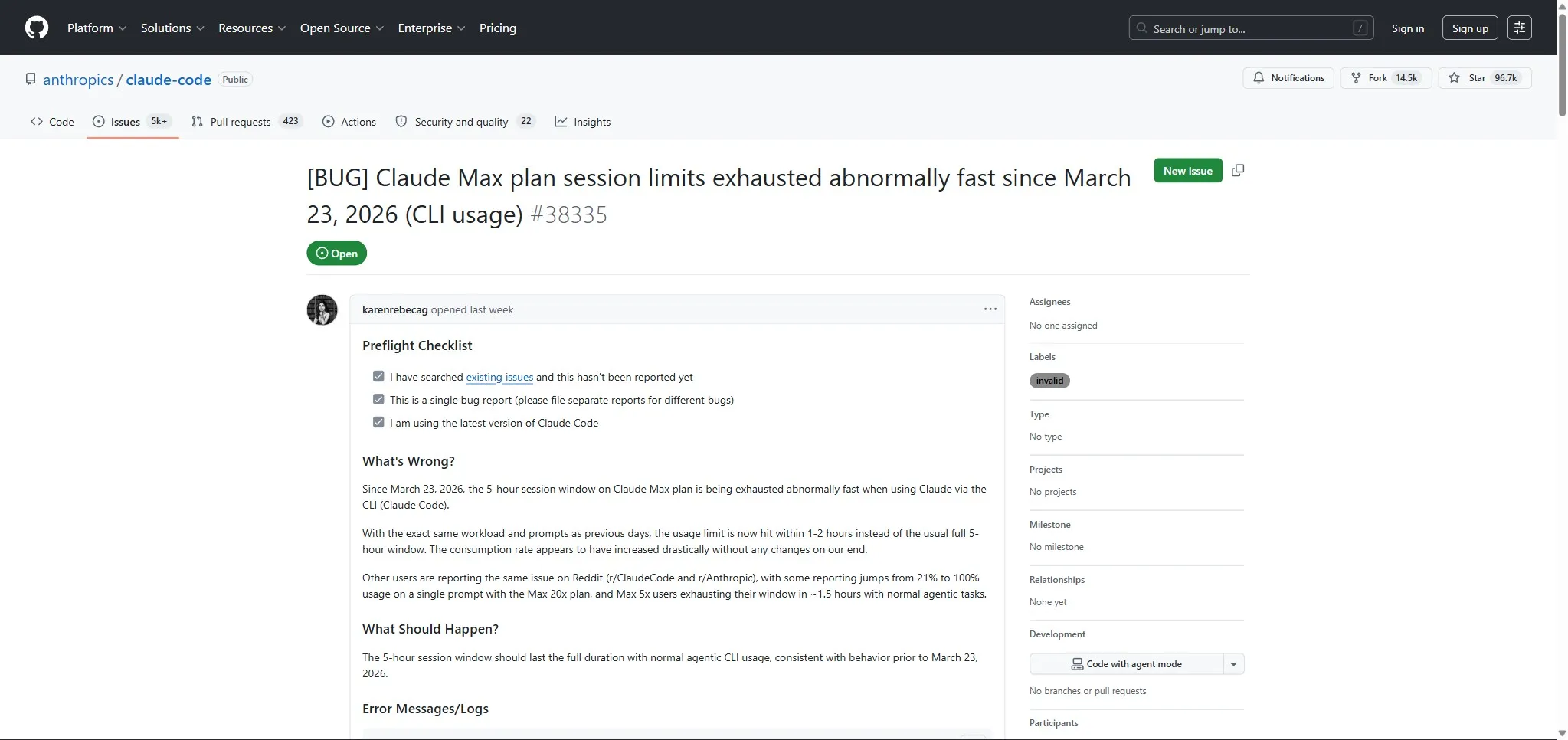
Mais Anthropic n’a jamais confirmé officiellement les deux bugs spécifiques. La product lead Lydia Hallie a déclaré que l’équipe “enquête activement sur la raison pour laquelle les utilisateurs atteignent leurs limites plus vite que prévu”. L’ingénieur Thariq Shihipar a reconnu que “les bugs de prompt cache peuvent être subtils”. Les GitHub issues #38335 (203 upvotes, 245 commentaires) et #40524 (150 upvotes) documentent le problème côté communauté.
Workaround : passer par npx au lieu du binaire standalone évite le bug d’attestation.
Ce qui est faux ou exagéré
LinkedIn a été inondé de posts sensationnalistes sur ce leak. Voici les claims les plus répandues, fact-checkées :
“L’IA est programmée pour cacher qu’elle est une IA” : partiellement vrai. Le mode Undercover empêche de leaker des noms de code internes, pas de “se faire passer pour un humain” de manière générale. C’est un garde-fou contre les fuites d’infos internes, pas un programme de tromperie.
“Anthropic peut fermer ton logiciel à distance” : exagéré. Claude Code vérifie sa licence et ses feature flags périodiquement, comme la quasi-totalité des logiciels SaaS modernes. Ce n’est pas un kill switch secret ; c’est du feature management standard.
“44 fonctionnalités cachées prêtes à être activées” : trompeur. Le code contient des feature flags pour des fonctionnalités à différents stades de développement. Certaines sont du code exploratoire, d’autres des tests internes. Ce n’est pas un arsenal secret ; c’est du développement logiciel normal avec du feature flagging.
“Le modèle Capybara génère 30% de fausses informations” : invérifiable. Des noms de code internes de modèles apparaissent dans le code, mais aucune donnée de benchmark n’a fuité. Ce chiffre ne vient de nulle part dans le code source.
“KAIROS permet à l’IA de rêver de ton code” : très exagéré. Le système de consolidation mémoire est un processus de nettoyage et d’organisation des observations. “Rêver” est une métaphore poétique ; le code fait du merge de notes et de la suppression de contradictions.
Claw-code : le clone qui bat des records
Le développeur coréen Sigrid Jin, déjà connu pour avoir consommé 25 milliards de tokens Claude Code en un an (profilé par le Wall Street Journal), a réécrit l’architecture en Python via un processus de “clean-room rewrite” en utilisant oh-my-codex.
Le repo claw-code a atteint 50 000 stars en 2 heures, dépassant 55 800 stars et 58 200 forks au 1er avril. Des audits indépendants confirment qu’il ne contient aucun code propriétaire Anthropic, aucun poids de modèle, aucune clé API.
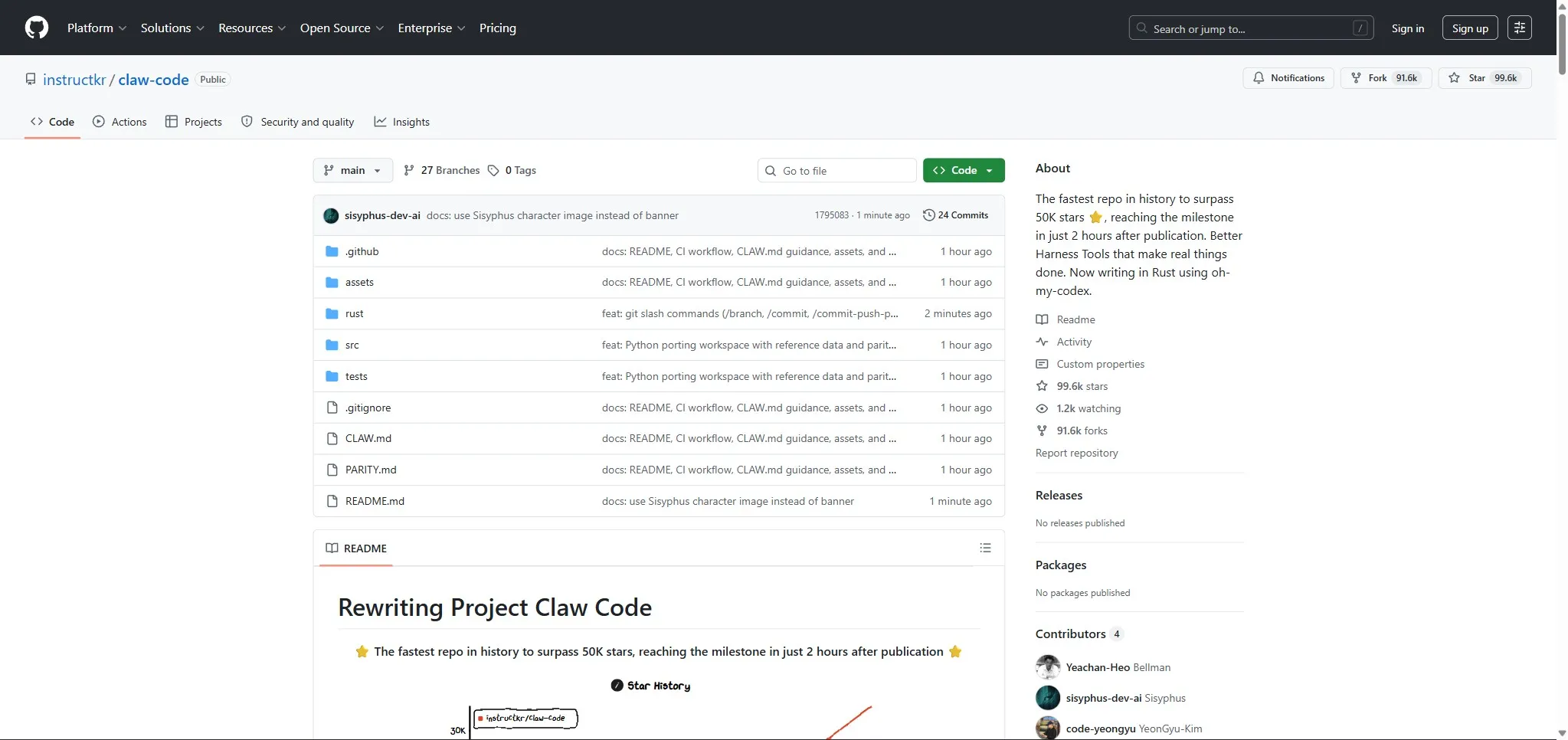
C’est un signal fort : l’architecture de Claude Code est suffisamment élégante pour être reproduite, mais la valeur réside dans les modèles, les données d’entraînement et l’infrastructure, pas dans le code TypeScript.
Ce que ça change pour toi
Si tu utilises Claude Code au quotidien (comme moi), voici les takeaways concrets :
-
Mets à jour vers la dernière version. Le bug de cache a été corrigé dans la v2.1.88+. Si tu utilises une ancienne version, tu paies potentiellement bien plus que nécessaire.
-
Préfère npx au binaire standalone si tu veux éviter les bugs liés au fork Bun custom.
-
La télémétrie existe, mais elle est standard. La détection de frustration et les analytics de session ne sont pas différentes de ce que font Cursor, VS Code, ou n’importe quel outil SaaS moderne.
-
Les features cachées arriveront. KAIROS, le mode voice, les agents en arrière-plan : tout ça est dans le pipeline. La question n’est pas si, mais quand.
-
Le prompt cache est ton meilleur ami. Comprendre comment le cache de prompts fonctionne (et casse) est crucial pour maîtriser tes coûts. Évite de mentionner des termes liés à la facturation dans tes conversations avec Claude Code si tu utilises le binaire standalone.
Ce que ça dit sur l’industrie
Ce leak n’est pas un événement isolé. C’est le deuxième incident de sécurité d’Anthropic en quelques jours (après une fuite accidentelle liée au modèle Mythos). Fortune a qualifié ça de pattern préoccupant pour une entreprise qui construit sa marque sur la sécurité et la confiance.
Le vrai enseignement, c’est que même les meilleures équipes d’ingénierie au monde ne sont pas à l’abri d’une erreur de configuration npm. Un .npmignore manquant et 512 000 lignes de code propriétaire deviennent publiques. C’est un rappel pour tous les développeurs : vérifiez ce que vous publiez sur les registres de packages.
Et pour Anthropic, c’est un test de crédibilité. Le bug de cache qui gonflait silencieusement les factures est plus dommageable pour la confiance que le leak lui-même. Les utilisateurs peuvent accepter une erreur de packaging. Ils acceptent moins bien de payer 20x le prix normal sans le savoir.
Pour aller plus loin
- FAQ Claude et Claude Code : tout savoir en 2026
- Installer Claude Code : le guide complet
- CLAUDE.md : bonnes pratiques
- Hooks Claude Code : automatiser votre workflow
Sources principales : The Hacker News, VentureBeat, The Register, Alex Kim’s blog, PiunikaWeb, Fortune, Decrypt, DEV Community

Pierre Rondeau
Développeur et indie builder. Je construis des produits et automatisations avec l'IA. Créateur de Claude Hub.
LinkedIn